Up for Tinderbox Weekend San Francisco?
It’ll be April 12-13 (Fri-Sat) or 13-14 (Sat-Sun). If you have a preference, Email me..
And if you’d be interested in a one-day Tinderbox event near Paris in the week of 29 April, let me know, too.
Up for Tinderbox Weekend San Francisco?
It’ll be April 12-13 (Fri-Sat) or 13-14 (Sat-Sun). If you have a preference, Email me..
And if you’d be interested in a one-day Tinderbox event near Paris in the week of 29 April, let me know, too.
I was checking Twitter late one night when — what did I see? — Next Restaurant announced the release of March tickets. (Next is the insanely cool Chicago restaurant which sells tickets instead of taking reservations. They have one menu. No choices, no worries.)
It’s an absurd indulgence, but I’ve found that I learn more from a spectacular dinner at someplace like Next than I do from a year’s worth of neighborhood dinners. So, we pretty much don’t eat out anymore when we’re in Boston and save up for the road.
Most people assume that testing is something you do after the engineering and construction are done, in order to check that the program runs and does what it should. That’s pretty much the way we used to build software. Some people still do that.
But modern dogma calls for extensive, automatic, built-in tests that are written alongside — or often before — the code. Each object that could possibly do something wrong gets tested in isolation. Each combination of objects that ought to work together gets tested together. All these tests are run all the time, automatically, so when something breaks you find out right away.
Ten years ago, “legacy code” meant “parts of the program written with punched cards, paper tape, stone knives and bearskins.” Since 2004
, it’s meant “parts of the program written before we used tests. Tinderbox 1.0 shipped in 2002, and so our code was still shiny and new when it became “legacy” code.
We’ve had three generations of tests in Tinderbox. The first tests, called Monkeys, were what we now call customer or acceptance tests. They exercised the whole system, focusing on a specific task or feature. The TextLinkMonkey, for example, opened a text window and and lots of links in order to check link editing behavior. The monkeys often (but not always) caught mistakes before they left Eastgate HQ, and they helped clarify what the program should do in situations where that wasn’t already clear. But they were also fragile and slow and it was too easy to overlook subtle problems — not to see, for example, that one of a dozen text links was shorter or bluer than it ought to have been.
Over time, the Monkeys were supplemented and then replaced by proper unit tests. Tinderbox got its own home-made unit test framework around 2005, and this rapidly chased the monkeys into the background. There were about 100 of these tests in Tinderbox 5.
Some of these tests were still too broad. There were lots of tests that depended on Hypertext and HypertextView, and that meant that most of Tinderbox had to be working in order for the test to get down to business. This wasn’t a problem for Tinderbox 5 development, but it was a real obstacle to Tinderbox 6 because so much of Tinderbox 6 has to start fresh. And Xcode now has its own unit testing framework which resembles, but also differs from, the custom-made Tinderbox test system.
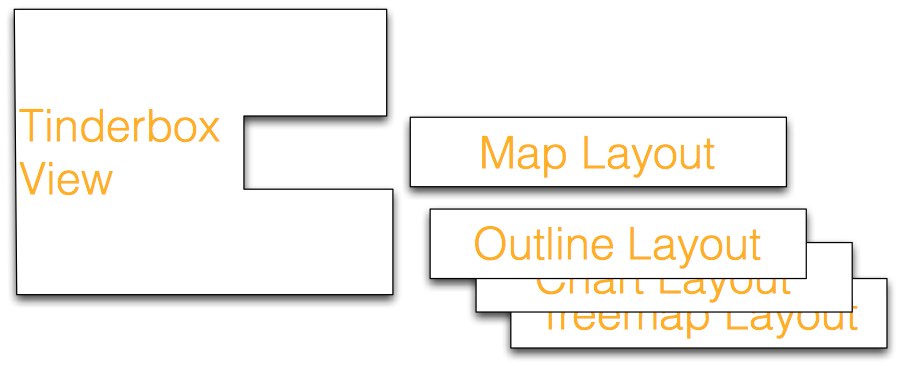
One priority right now is to get better testing for smaller objects. For example, each Tinderbox view has a small utility object, a LayoutPolicy, that knows how to arrange notes in that kind of view. The OutlineLayoutPolicy, for example, knows about the geometry of outlines, and TreemapLayoutPolicy knows about the geometry of tree maps.
The old tests tested the view after it had been assembled with the appropriate LayoutPolicy. This has worked fairly well, to be sure, and it’s not that hard to do. But over the years, some of the layout policies had grown shaggy and complicated, and the layout policies had all become too closely coupled with the views. This is annoying because improving a layout policy meant needing to recompile a dozen or more classes, and that slows things down. For Tinderbox Six, coupling became a real nuisance; you couldn’t really build the view classes until the layout policies were working, but you couldn’t know whether the layout policies were working until you had a view class to test them with. For a few days, I was holding a hammer in one hand, a plank in one hand, and needed to reach for a nail…
Fixing these dependencies has been good for the code; the LayoutPolicy classes are now slimmer and easier to understand. But it knocked the development schedule back a week, maybe two, in order to improve a part of the system that was working fine. This was probably necessary to pay down technical debt, but I sure could use a week or two if you have some to spare.
The first part of How Software Is Built Today focused on polishing a detail of the user interface. Polish matters, but a lot of our software these days is all on the surface. That’s great for tiny applications that everyone needs, like an alarm clock or a telephone dial, because everyone can share the costs of getting everything exactly right.
But Tinderbox Six isn’t an alarm clock. There are lots of moving parts behind the user interface. Some people always think that’s a sign of malign design, that everything should be made simple. But things aren’t always simple, and anyway the people who want simple software are the people who hate us.
The point is to make things as simple as they can be, and no simpler. Everyone’s everyday knowledge work is incredibly complex; if we want to even begin to help with that, we’re going to have some complexity. Here’s an example of another piece of Tinderbox and its evolution.
A Tinderbox note is a collection of lots of attributes, each of which has a value. The name of the note is an attribute called $Name. The note has a $Color. It might have a $Prototype. If it has some $Text, you can find out things about it like its $WordCount. Because everything’s a value, it’s easy to say things like “Make all my overdue tasks red,” or “Keep old reminders for a month, and then move them to the archives.”
Or, to take an example from the recent discussion of Book Notes In Tinderbox, “Assume that I start reading a book the day I enter it in Tinderbox. If I delay for some reason, I’ll correct it later.”
Now, from the very beginning I could see that we’d need several kinds of values:
and we need to be able to move easily between them:
Value *urlValue=new URLValue(…);
string s=urlValue->AsString()
We can ask any kind of Value to represent itself as a string, a number, a Boolean, whatever.
Originally, everything in Tinderbox used Values directly, so the code was filled with things like this:
Value* v=Get(“Xpos”);
int x=v->AsNumber();
And these eventually get written as Get(“…”)->AsNumber(). And that leads in turn to Get(“…”) ->AsAction() -> EvaluateFor(thisNote,withThatContext). The chain of objects starts to read like a short story.
Now, these chains violate something called The Law Of Demeter, which everyone agrees isn’t really a law. It’s really The Suggestion of Demeter. But at some point, all those arrows means that the object you’re working on – say, the object that knows how to draw the bevels around the edge of a note – needs to know all about how actions work, and how values work. That’s a lot of knowledge for a gizmo that paints bevels. Pretty soon, everything needs to know about everything. That’s lousy design.
So we can hide all almost everything about Value inside the Note class. Now, no one calls Get(“…”) to get a value; instead, you call GetString(“…”) to get a string, and it gets the value for you. This is like Don Draper and the phone; he doesn’t fuss with a phonebook, he asks a secretary to call Joe. So, now hardly anything needs to know about Value itself, and that’s good because Value gets complicated and tricky. (The disadvantage of having everything be a value is that everything is a Value, so there are lots of values and lots of little improvements in values. A lot of the time, when a new Tinderbox has come out and it’s a lot faster, that’s been some sort of improvement in handling Values.)
The disadvantage, though, is that where we used to have one all-purpose method to Get() a value, now we have GetString() and GetNumber() and GetURL() and whatnot. And everything that has values needs to have each of these methods. And they all have to work, and they all have to be fast. That’s lousy design too – just a little less lousy than the first one.
Most of the time, a note has a value. We just want to look at it, almost always to convert it to a string or a number or an aardvark. So the note owns a value, and Get() just takes a peek. But there are a few attributes where that doesn’t work. For example, $WordCount might change at any moment, either because you’re typing, or because some rule changed the text. We don’t want to make a new Value (and delete the old one) every time you press a key. So we make a new Value object for $WordCount when someone asks for it, and hand it to whoever wants a peek. But we still own that Value, even though we’ll never use it again. So we have a deal with the customer:
We hold onto ownership of the temporary Value we just created. You can do whatever you want with it, but you can’t keep it; you have to give it back right away, because you’re just looking. And once you give it back, we’ll hang onto it until someone else asks for a $WordCount, and when they do we’ll delete the old Value and make a fresh one.
And that works just fine. Except there’s been one special attribute that forgot to do this back in 2006 or so. It just started giving away Values to whoever came by, handing them out like canapés. This created a small memory leak, one that was a bear to track down because it’s small and it only leaks when you use this specific attribute.
Now, I got started with lab software for tiny embedded computers with almost no memory to spare, so I’m really fierce about leaks. But we’ve been leaking these little values for years, and now that everybody has gigabytes of memory, hardly anyone noticed. But it’s bad style, and today (finally!) I found it.
Over time, hunting this has taken days of work. (You could say that we should have caught it with unit tests, but we didn’t do Test Driven Development in 2002 and neither did you.) Again, as in Part I, the business case for doing it right is weak. (It was weaker still in 2002, when no one’s computer stayed up for the weeks it takes for the leak to make a dent, even if you’re using the defective Attribute.) It’s even harder to recover the costs here. (Yes, getting it right in the first place would have been nice, but there are currently 24 subclasses of Attribute and that’s a tricky number – big enough that one is bound to be wrong, but too small to justify automating the subclass generation or to merit condensing all those classes into the parent.)
What puzzles me most is, where do people learn how to do this? When to extract classes and when not, when to ignore Demeter, when to hunt that last leak? I try sometimes to talk to people at conferences, but mostly this kind of implementation is not what they do. I tried this years ago at a hypertext workshop and got blank stares — partly because, even at the Hypertext conference, hardly anyone was building systems anymore. In a busy year, the roster might have included Cathy, Frank, Haowei, Polle, Peter, Claus, Kumiyo, and me. I think there have been years when I was pretty much it.
This also makes me marvel at the ability of someone like Keith Blount (Scrivener) who learned this craft so quickly, with so few resources available, because he wanted to get something built.
It ought to be simpler, but no simpler than it can be.
This longish post has about 1362 words, which I found out by checking $WordCount. It was composed and edited entirely in Tinderbox Six, which stayed up throughout. Another milestone.
Don’t miss Jack Baty’s new, minimalist weblog. It’s made with Tinderbox, and it’s good to see people coming back to blogging with Tinderbox.
Hit of the week: Digital Record Keeping.
Two feet of snow. Not counting the drifts. No subways, no busses, no cars.
So far, we’re suffering from critical shortages of triple sec, and the supply of onions and of eggs are getting low. Garlic reserves are not everything that could be wished, either.
But we can hold out!

I received a (fairly) nice referee report yesterday, so a paper I co-authored with Claus Atzenbeck, Stacey Mason, and Marwa Al-Shafey will be presented at Hypertext ’13. I’m a little miffed, though, because it was clear that none of the reviewers were familiar with my recent papers for Hypertext, a series I think of as my Big Three:
These, along with the Genre piece on Designing a New Media Economy, were a ton of work. As far as I can see, they’ve had no impact at all.
I'm tempted to wrap these up between paper covers. If I do and you’d like a copy, Email me. Thanks.
This is frustrating not just because of the “do you know who I am!” aspect, but because it’s becoming very difficult to have a discussion amongst papers. Because people don’t really know the literature, they restate their opinions when they ought to be responding to, and building on, the work you and they have already done.
One of the reviewers pointed to a paper from Hypertext ’12 that we ought to have cited. I nodded. And then I realized that I myself haven’t read that paper.
This could easily be blamed on “kids today,” on declining standards of scholarship. Perhaps it’s a complain of an old fogey who imagines things used to be better.
But I think the real problem is that we don’t have program committees that actually meet anymore. In the old days, you’d have ten or twenty people in a room, in person, and you’d discuss every paper. That meant you heard your colleagues talk all day about papers, about their strengths and weaknesses, about whether the work was really original or really convincing. It instilled a habit of argument, of knowing what’s been done and what’s new. At the same time, because some papers were mentioned time and again, it built a body of shared knowledge for the field.
This helps teach everyone How To Do It. You can learn a lot from good discussions of bad papers, and even more from thorough vetting of fairly good papers.
Now, program committee members never see each other. They write reviews and submit them to EasyChair and the wheels go round. For many conferences, I’m not sure that reviewers always read other reviews, or that anyone pays much attention when the reviewers basically agree.
This needs to be fixed. I’m not sure how to do it, or if it can be done, but if we don’t manage to address this problem, we’re not going to have a research discipline and we won’t have any claim to being a science.
Web Science 2013 has now received a terrific (and large!) array of research submissions. The program committee’s task is to sort these out, to choose the best for the program and also to direct researchers toward ways to improve their results.
In Computer Science, conference papers matter — both in terms of directing research and in shaping careers. Moreover, we have only three days in Paris; we need to select the best and most interesting research and arrange for its presentation in the most interesting and efficient form.
I’ve written a guide to reviewing conference papers. I also direct the attention of my fellow computer scientists to Bertrand Meyer’s essay in the current CACM on the incidence of wrong and mean-spirited reviews.
Web Science is wildly interdisciplinary, ranging from computation to sociology, literature, philosophy, law, and the arts. The program committee contains lots of people who aren’t computer scientists; these remarks are meant for them.
Conference review is not grading papers, or jurying a literary prize, or writing a book review. Our core concern is good science and sound engineering. If we have a paper:
THE WHIFFLESTONE TRUSS
The Pemberly approach to bridge design has always been appreciated for its economy and simplicity of construction. Unfortunately, Pemberly bridges have frequently turned out to be unstable. The Whifflestone adds an Anson Cap to each Cobb Tie; simulation and analysis both confirm that the resulting structure lacks the characteristic Pemberly failure modes while adding less than 3% to the structure’s weight.
Your first care in reviewing this paper is simply this: if readers rely on the paper to build a bridge, is that bridge liable to fall down?
The program chairs and subchairs sent you this paper because some aspect of the work intersects your expertise. Perhaps the argument depends on traditional Chinese bridge construction, or on Ruskin’s aesthetic theories; we can find engineers to check the math, but how many bridge builders know China or Ruskin?
We’ll sometimes ask you to stretch a bit, knowing that parts of a paper might be well outside your field but nonetheless desiring for your opinion.
Mistakes happen. If you can’t make heads or tails of the paper, we might have been confused. (Oops! Wrong Barthelme!) Let us know; we’ll reassign it.
First, insist on clear, accurate, and complete statement of the facts. Where in political writing, for example, we allow some latitude for the author’s stance and bias, here we expect statements of fact to be scrupulous.
Impact is important. Does this result matter? Is it already known? Does this new knowledge suggest new avenues of research?
Next, scholarship matters. Precedents, related work, and alternative views should be identified, cited, and fairly appraised. Many students wrongly believe the point of citing related work is to argue for the superiority and originality of their own. This is a mistake to be gently but firmly corrected.
Good writing helps. As a discipline, we adopt a very generous attitude to writing – too generous in my opinion, but pay no attention to me. Many of our papers are written by people with a tenuous grasp of English prose, and others by people to whom English is a new language. We try to accommodate everyone and to avert our eyes when we must, but some papers may be incomprehensible. If a paper is impossible to understand, say so.
Try especially to note two kinds of defect:
Our model reader is highly motivated; she wants to build that bridge and she wants it not to fall down. In consequence, we put up with passive construction and predictable organization. If you see a way to improve a paper, do suggest it. And if you encounter a paper that seems particularly well written, or that has an especially confident or amiable voice, do mention that.
We’d also like your thoughts about the best way to present this work at the conference. Formats include:
Resist the temptation simply to allot more time to better work. A brilliant and important result may require very little time to present effectively. In other cases, a useful though minor discovery may benefit from having sufficient time to explain its novel methodology and to explore its potential consequences.
Reviews do not respect persons, but presentation mode may. When it comes to science and scholarship, the most senior researcher is held to precisely the same standard as the least-known student. We don’t attempt double-blind reviews but we have a strong tradition of not caring whether a paper is written by famous or influential persons. In recommending a presentation mode, however, it can be useful to know that Prof. Anson is an engaging speaker, or that Dr. Banks writes with an unusually amiable and confident voice.
Note that, unlike many conferences, presentation mode at Web Science does not affect publication mode. We can give a 30 minute slot to a short paper that needs the time, and we can allow a 7-minute pecha kucha to summarize a full-length paper with appendices and figures.
Conflicts of interest include anyone who works at your organization, current and former graduate students, former graduate advisors, and current or former romances. F. Scott Fitzgerald has a conflict with Zelda, with his editor Maxwell Perkins, and with his protégée Edmund Wilson. He doesn’t have a conflict with William Faulkner even though they both published in the Saturday Evening Post, or with Dorothy Parker, even though they often drank together. When in doubt, ask.
Reviews are anonymous, and are typically shared with the authors of the paper. Private remarks may be addressed to the committee, and these will not be shared.
Papers for review are confidential. Don’t cite them, don’t discuss them, don’t use their results in your own research. You may consult with colleagues if you need their expertise, but they also are to be bound be these constraints.
It is helpful to begin reviews with a sentence or two that summarizes the main contribution of the paper. This helps, among other things, to ensure against clerical errors.
Please submit your reviews on time.
After reviews are submitted, we may ask for additional discussion to resolve disagreements and discrepancies. Each review is read with care and contrasting opinions are weighed by the chairs. Quite often, we’ll ask reviewers to reexamine their opinion in light of contrasting views in order to establish consensus or to avoid being swayed by enthusiasm or placing undue emphasis on a detail. Your participation in these discussions may prove especially significant.
Years ago, I was quite interested in whether or not the better football team consistently won games that matter.
In baseball, an inferior major league team will often beat a superior team. Even the very best team would be expected to lost about a third of its games to the very worst. That’s why you need to have 162 games in the season, and a 7-game series, to have any reasonable hope of establishing who deserves to win.
Football isn’t like that; in football, I think most people believe that a very good team will almost always defeat a bad one. But the playoffs are giving us reason to doubt.
This is a long-term threat to football; if the games are mostly going to be decided by lucky breaks and the referees, it’s harder to care. (I think everyone would agree that the refs could have given the game to SF if they were so inclined.) This year’s Super Bowl was filled with defensive ads (“We’re doing research to make the sport safe for your kids!” “We’re not sexist anymore!”), but none of this will matter if the games don’t.
A wryly over-the-top mystery set in the midst of a power struggle in a 1990s Women’s College in Cambridge. Our hero, the Bursar, brings an old friend into the school to lend a hand with the political infighting; when the Mistress is murdered, things get badly out of hand. After a reverse in a faculty meeting, suffered at the hands of the women’s studies/queer studies faction, the Bursar exclaims “Time and again we were warned of the Dykes!” A good time is had by all.
The incredibly ghastly cover doesn’t matter in the $2.99 Kindle edition.

